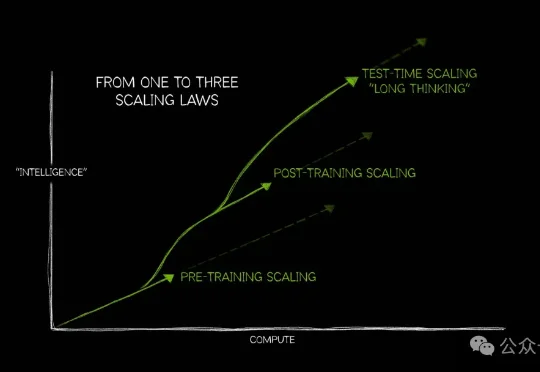
把思考折叠进序列:WeLM 617B MoE的隐式Scaling路径
把思考折叠进序列:WeLM 617B MoE的隐式Scaling路径新智元报道 大模型变强,过去靠两条路。 做大——Scaling Law出现后,参数从百亿推向千亿,算力支出一路飙升。 想久——o1带火思考模型,用更长的思维链、更多推理时间换结果。 问题是,除了Sca
来自主题: AI技术研报
8216 点击 2026-07-24 15:54
 搜索
搜索
新智元报道 大模型变强,过去靠两条路。 做大——Scaling Law出现后,参数从百亿推向千亿,算力支出一路飙升。 想久——o1带火思考模型,用更长的思维链、更多推理时间换结果。 问题是,除了Sca

模型决定起点,数据定义终局。

作为WAIC 2026最受关注的论坛,由商汤科技承办的“基座大模型架构创新与生态合作论坛”吸引了无数AI研究者、产业专家和投资机构的目光。因它直面了当前大模型行业最核心的焦虑:当Scaling Law在逼近物理极限,多模态究竟是破局的“解药”,还是新瓶装旧酒的延伸?

今天,小米刚刚扔出一颗“深水炸弹”——Xiaomi-Robotics-1具身基座模型,试图改变这一局面。Xiaomi-Robotics-1基于10万小时真实世界操作轨迹进行预训练,再用约1.1万小时跨本体数据完成后训练。据悉,这是国内首次在机器人策略模型中,对Scaling Law进行较为完整的系统验证。
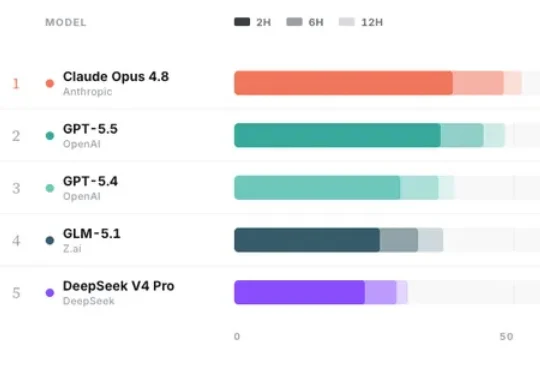
7月2日,字节 Seed 发布了一个 Agent评测项目 EdgeBench。看起来又是一个 benchmark,但它问了一个其他榜单不问的问题。EdgeBench 的切口就是把盲区里的东西放进评测,解答一个问题:把Agent扔进一个陌生环境,12小时后,你能变强多少?
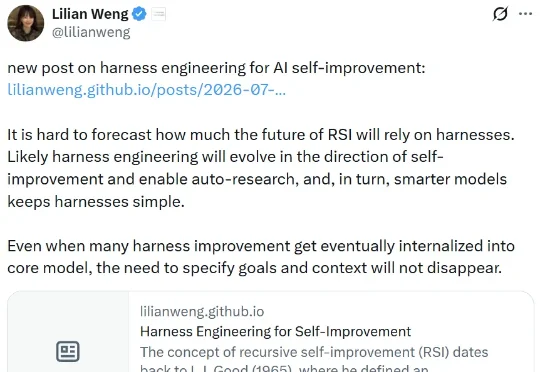
刚刚,翁荔(Lilian Weng)又更新博客了!距离她上一次更新《谨慎对待 Scaling Law》还不到 10 天。这一次,她书写的主题是当前大热的 Harness Engineering,聚焦的正是当下 AI 研究最前沿一个环节:当模型本身的智能已经足够强大时,真正决定它能走多远的,或许是包裹在模型外面的那层「Harness」也就是负责编排模型思考、调用工具、管理上下文、评估结果的那套系统。
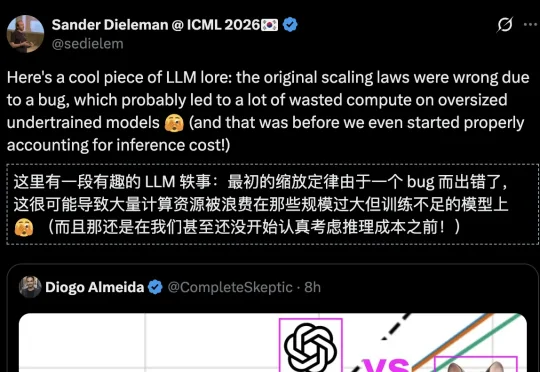
OpenAI误导了整个AI圈好几年!过去五年,整个AI行业都被Scaling Law推着往前冲。现在,有人站出来说:这条曲线,一开始就错了。刚刚,他发出一篇博客,标题冷得发指——《Scaling Laws, Honestly》。

OpenAI首席研究官Mark Chen释放了一个强烈信号:OpenAI 并不认为scaling laws已经失效,恰恰相反,预训练、数据工程、推理训练和更长任务链条,仍是通向AGI的主干道路。
刚刚,翁荔(Lilian Weng)的博客 Lil'Log 终于更新了!要知道,自从她联合创立了 Thinking Machines Lab 之后,她那让许多人受益良多的博客就鲜少更新了——距离她上一次更新,已经过去了 13 个月。

过去的大模型 scaling law 通常回答的是:当模型参数量、数据量和训练计算量增加后,loss 会如何下降。